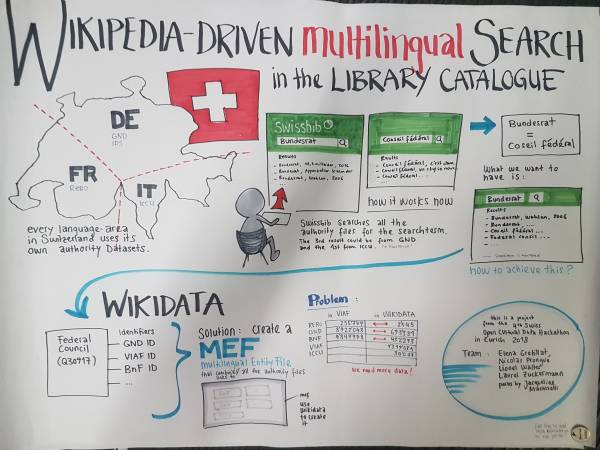
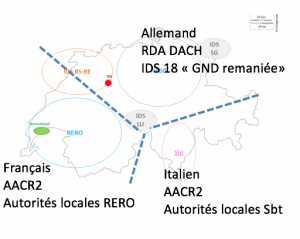
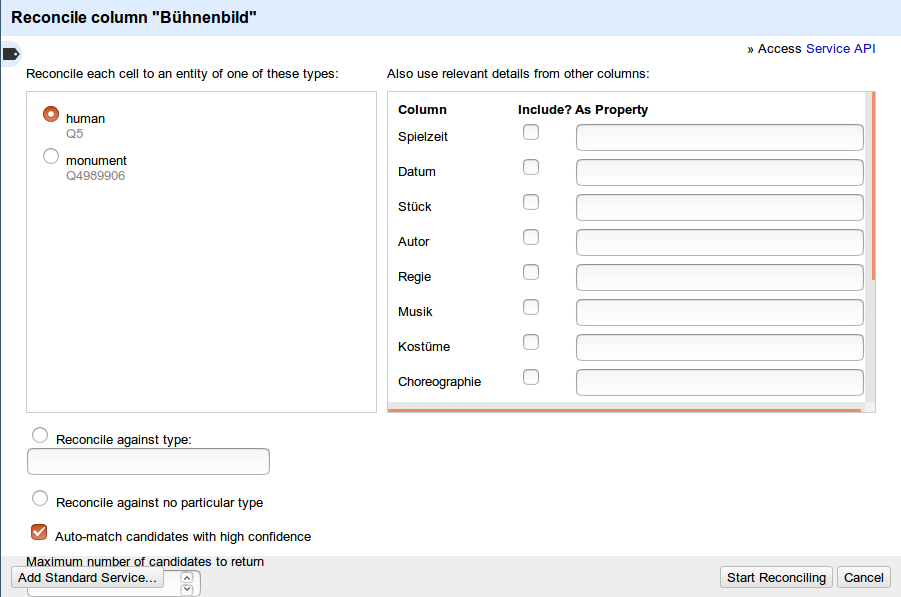
In Switzerland each linguistic region is working with different authority files for authors and organizations, situation which brings difficulties for the end user when he is doing a search.
Goal of the Hackathon: work on a innovative solution as the library landscape search platforms will change in next years.
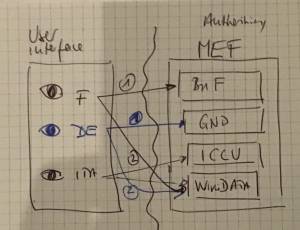
Possible solution: Multilingual Entity File which links to GND, BnF, ICCU Authority files and Wikidata to bring end user information about authors in the language he wants.
Steps:
-
analyse coverage by wikidata of the RERO authority file (20-30%)
-
testing approach to load some RERO authorities in wikidata (learn process)
-
create an intermediate process using GND ID to get description information and wikidata ID
-
from wikidata get the others identifiers (BnF, RERO,etc)
-
analyse which element from the GND are in wikidata, same for BnF, VIAF and ICCU
-
create a multilingual search prototype (based on Swissbib model)
Data
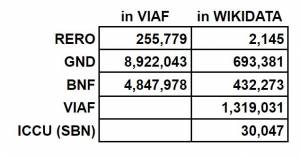
Number of ID in VIAF
Number of ID in Wikidata from
Query model:
wikidata item with rero id
#All items with a property
# Sample to query all values of a property
# Property talk pages on Wikidata include basic queries adapted to each
property
SELECT
?item ?itemLabel
?value ?valueLabel
# valueLabel is only useful for properties with item-datatype
WHERE
{
?item wdt:P3065 ?value
# change P1800 to another property
SERVICE wikibase:label { bd:serviceParam wikibase:language
"[AUTO_LANGUAGE],en". }
}
# remove or change limit for more results
LIMIT 10000
Email from the GND :
There is currently no process that guarantees 100% coverage of GND entities in wikibase. The existing links between wikibase and GND entries come mostly from manually edited Wikipedia entries.
User Interface
There are several different target users: the librarians who currently use all kinds of different systems and the end user, who wants to search for information or to locate a book in a nearby library.
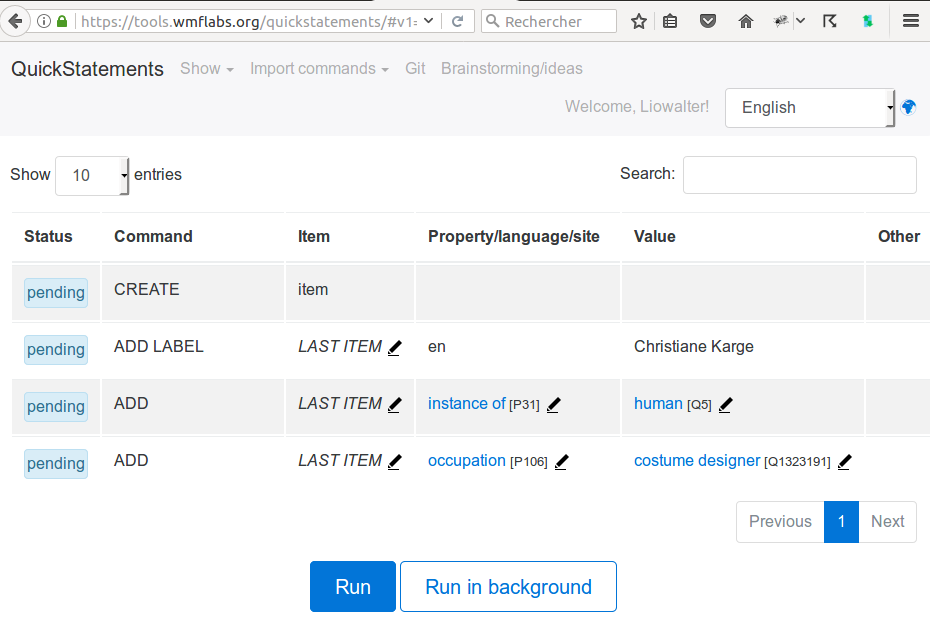
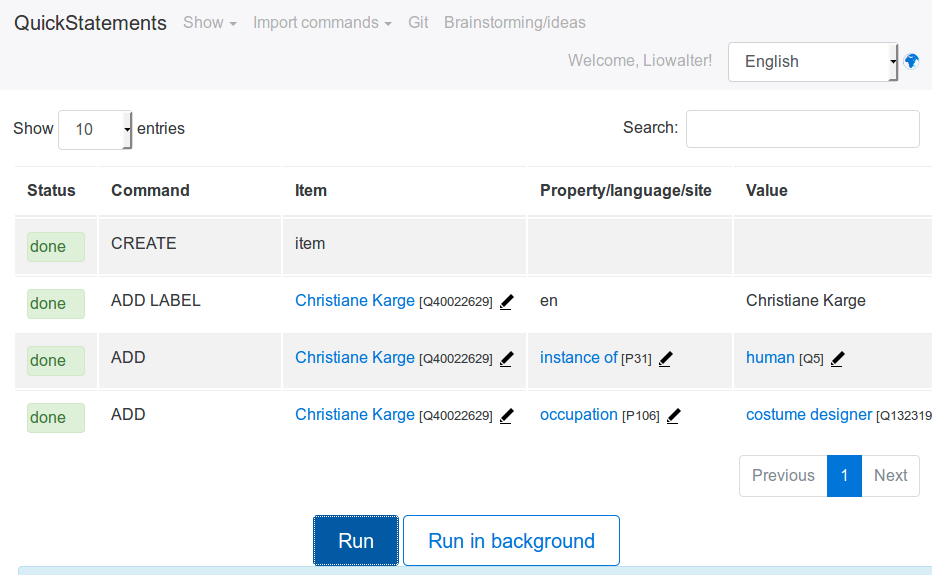
Librarian: The question of process is the key challenge concerning the librarian user. At present some Swiss librarians create authority records and some don't. New rules and processes for creating authority files in GND , BNF, etc will change their work methods. The process of creating local Swiss authority files will be entirely revamped. Fragmented Swiss regional authority files will disappear, and be replaced by either the German, French, Italian, American etc national authority files or by direct creation in Wikidata by the local librarian. (Wikidata will serve as central repository for all autority IDs).
End User
The model for the multilingual user interface is SwissBib, the “catalog of Swiss univerity libraries, the Swiss national library, several cantonal libraries and other institutions”. The objective is to keep the look and functionalities of the existing website, which includes multilingual display of labels in English, French, German and Italian.
What changes is the source of information about the author which will in the future be taken from the BNF for French, the GNB for German, and LCCN for English. (In the proof of concept pilot, only the author name will be concerned.)
The list of books and libraries will continue to function as before, with no changes.
In the full project, several pages must be modified:
* The search page (example with Joel Dicker): https://www.swissbib.ch/Search/Results?lookfor=joel+dicker&type=AllFields
* The Advanced search page https://www.swissbib.ch/Search/Advanced
* The Record Page: https://www.swissbib.ch/Record/48096257X
The Proof on Concept project will focus exclusively on the basic search page.
Open issues
The issue of key words remains open (at present they are from DNB, which works for German and English, but does not work for French)
The question of an author photo and a bio is open. At present very few authors have a short bio paragraph associated with their names. Should each author have a photo and bio? If so, where to put it on the page?
Other design question: Should the selection of the language of the book be moved up on the page?
Prototype
(Translations from Wikidata into French)
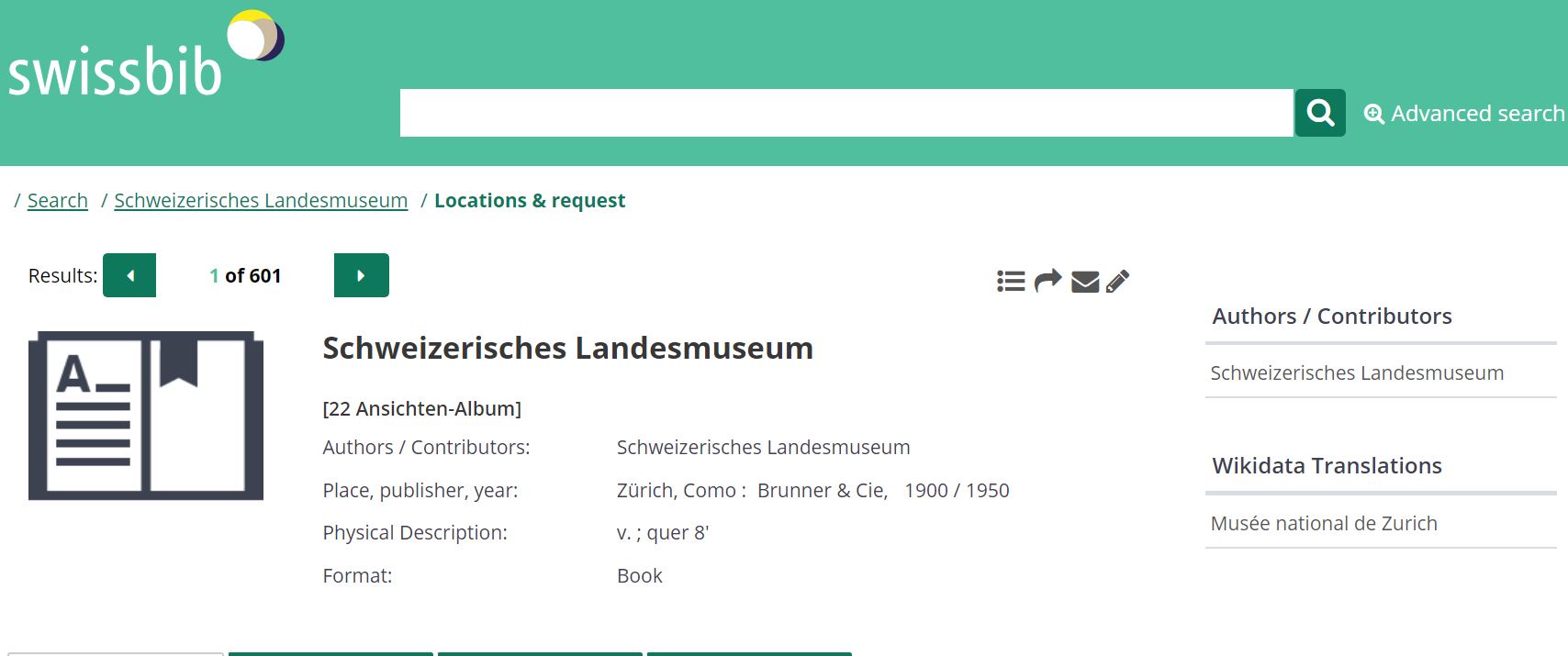
1. Schweizerisches Landesmuseum
http://feature.swissbib.ch/Record/110393589
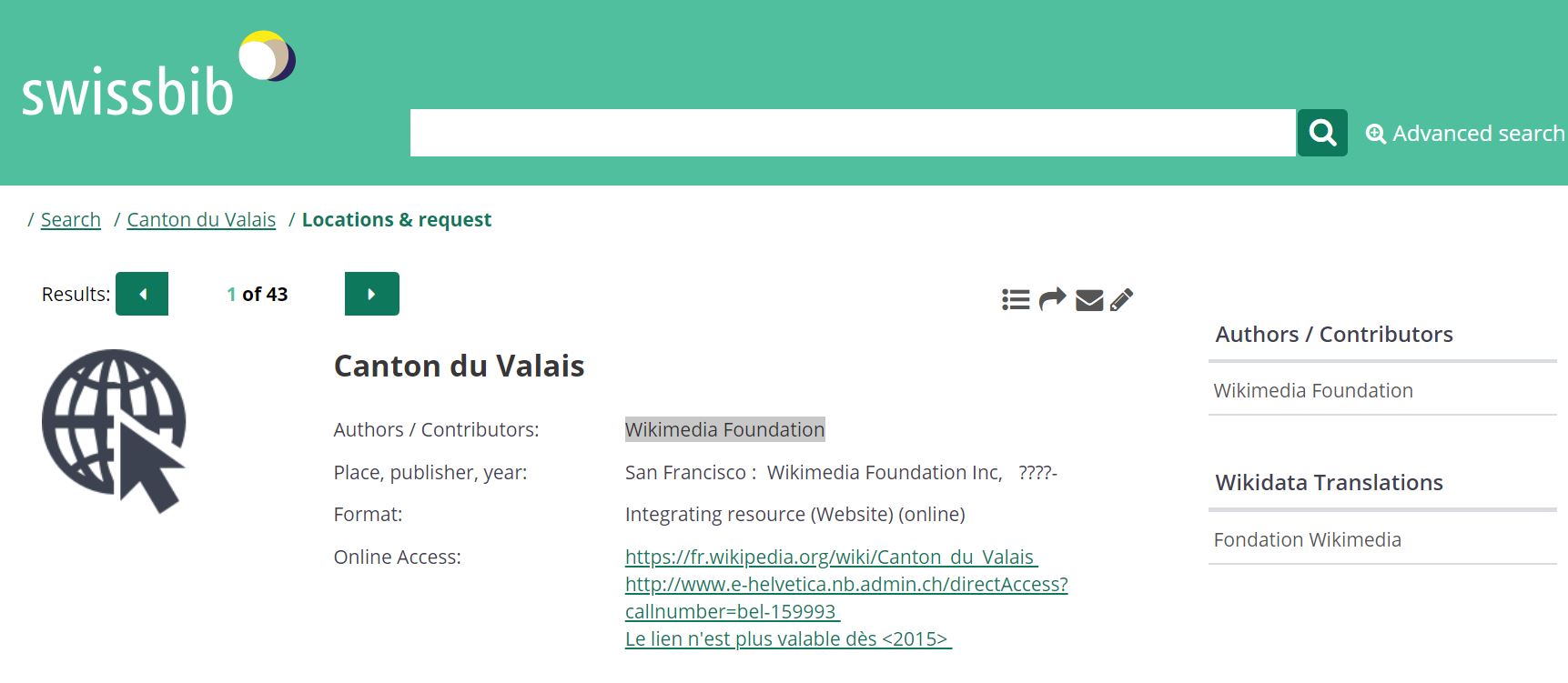
2. Wikimedia Foundation
http://feature.swissbib.ch/Record/070092974
3. Chocoladefabriken Lindt & Sprüngli AG
http://feature.swissbib.ch/Record/279360789
ATTENTION: Multiple authors

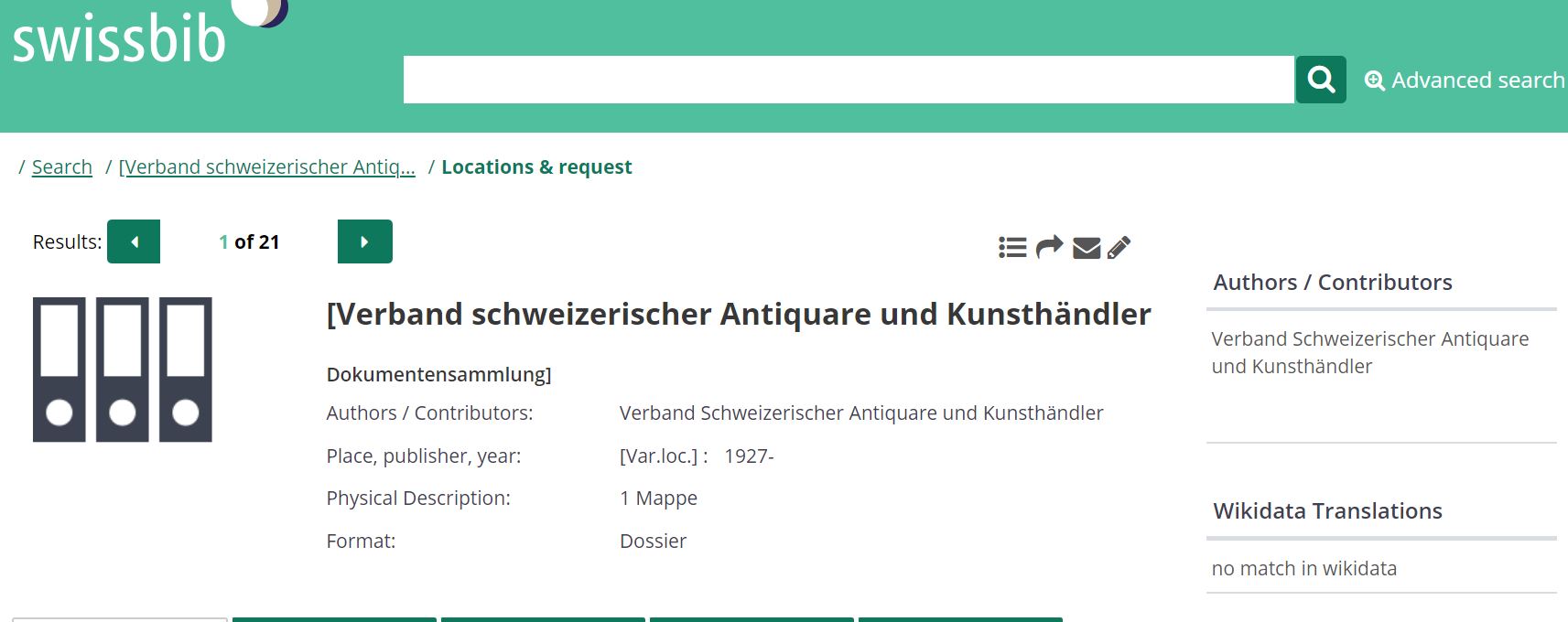
4. Verband schweizerischer Antiquare und Kunsthändler
ATTENTION: NO French label in Wikidata
http://feature.swissbib.ch/Record/107734591
Methods
Way of getting BNF records via SRU from Wikidata
http://catalogue.bnf.fr/api/SRU?version=1.2&operation=searchRetrieve&query=aut.ark%20all%20%22ark:/12148/cb118806093%22&recordSchema=unimarcxchange&maximumRecords=20&startRecord=1
Instruction: add prefix “ark:/12148/cb” to BNF ID in order to obtain the ARK ID
Lookup Qcode from GND ID
SELECT DISTINCT ?item ?itemLabel WHERE {
?item wdt:P227 "1027690041".
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}
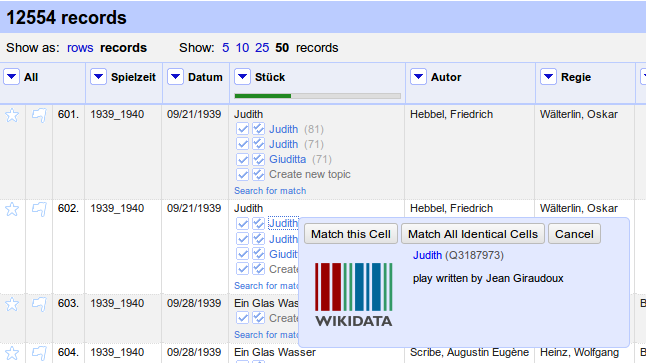
Integration of RERO person/organisation data into Wikidata
Methodology
4 cases
1. RERO authorities are in Wikidata with RERO ID
2. RERO authorities are in Wikidata without RERO ID but with VIAF ID
3. RERO authorities are in Wikidata without RERO or VIAF ID
4. RERO authorities are not in Wikidata
Demo / Code / Final presentation
Team
























 Les Archives photographiques de la Société des Nations (SDN) — ancêtre de l'actuelle Organisation des Nations Unies (ONU) — consistent en une collection de plusieurs milliers de photographies des assemblées, délégations, commissions, secrétariats ainsi qu'une série de portraits de diplomates. Si ces photographies, numérisées en 2001, ont été rendues accessible sur le web par l'
Les Archives photographiques de la Société des Nations (SDN) — ancêtre de l'actuelle Organisation des Nations Unies (ONU) — consistent en une collection de plusieurs milliers de photographies des assemblées, délégations, commissions, secrétariats ainsi qu'une série de portraits de diplomates. Si ces photographies, numérisées en 2001, ont été rendues accessible sur le web par l'

















































{kind=link}