MICHA RIESER, Wikipedian in Residence; Project Manager Open Cultural Hackathon, Bern 2015
Il portale professionale svizzero per le scienze storiche
Swiss Open Cultural Data Hackathons
Micha Rieser

Infoclio Interview
Venerdì, 27. Febbraio 2015
Matthias Nepfer

Infoclio Interview
Venerdì, 27. Febbraio 2015
MATTHIAS NEPFER, Head of innovation and information management, Swiss National Library; Co-Organizer Open Cultural Hackathon, Bern 2015
Beat Estermann

Infoclio Interview
Venerdì, 27. Febbraio 2015
Beat Estermann, E-Government Institute, University of Applied Sciences Bern; Dataset head Open Cultural Hackathon, Bern 2015
Frédéric Noyer

Infoclio Interview
Venerdì, 27. Febbraio 2015
Frédéric Noyer, State Archives Neuchâtel; Communication Head Open Cultural Hackathon, Bern 2015
Alain und Laura sind neue Medien

infoclio.ch Vorträge
Sabato, 28. Febbraio 2015
Two comedians take a poetic journey along selected cultural datasets. They uncover trivia, funny and bizarre facts, and give life to data in a most peculiar way. In French, German, English and some Italian.
Data
- http://www.openstreetmap.org
- http://make.opendata.ch/wiki/data:glam_ch#pcp_inventory
- http://make.opendata.ch/wiki/data:glam_ch#carl_durheim_s_police_photogra...
- http://make.opendata.ch/wiki/data:glam_ch#swiss_book_2001
Team
- Catherine Pugin
- Laura Chaignat
- Alain Guerry
- Dominique Genoud
- Florian Evéquoz
Links
Tools: Knime, Python, D3, sweat, coffee and salmon pasta

Artmap

infoclio.ch Vorträge
Sabato, 28. Febbraio 2015
Simple webpage created to display the art on the map and allow to click on each individual element and to follow the URL link:
Find art around you on a map!
Data
Team
- odi
- julochrobak
- and other team members
catexport

infoclio.ch Vorträge
Sabato, 28. Febbraio 2015
Export Wikimedia Commons categories to your local machine with a convenient web user interface.
Try it here: http://catexport.herokuapp.com
Data
- Wikimedia Commons API
Team
- odi
- and other team members
Related
At #glamhack a number of categories were made available offline by loleg using this shell script and magnus-toolserver.
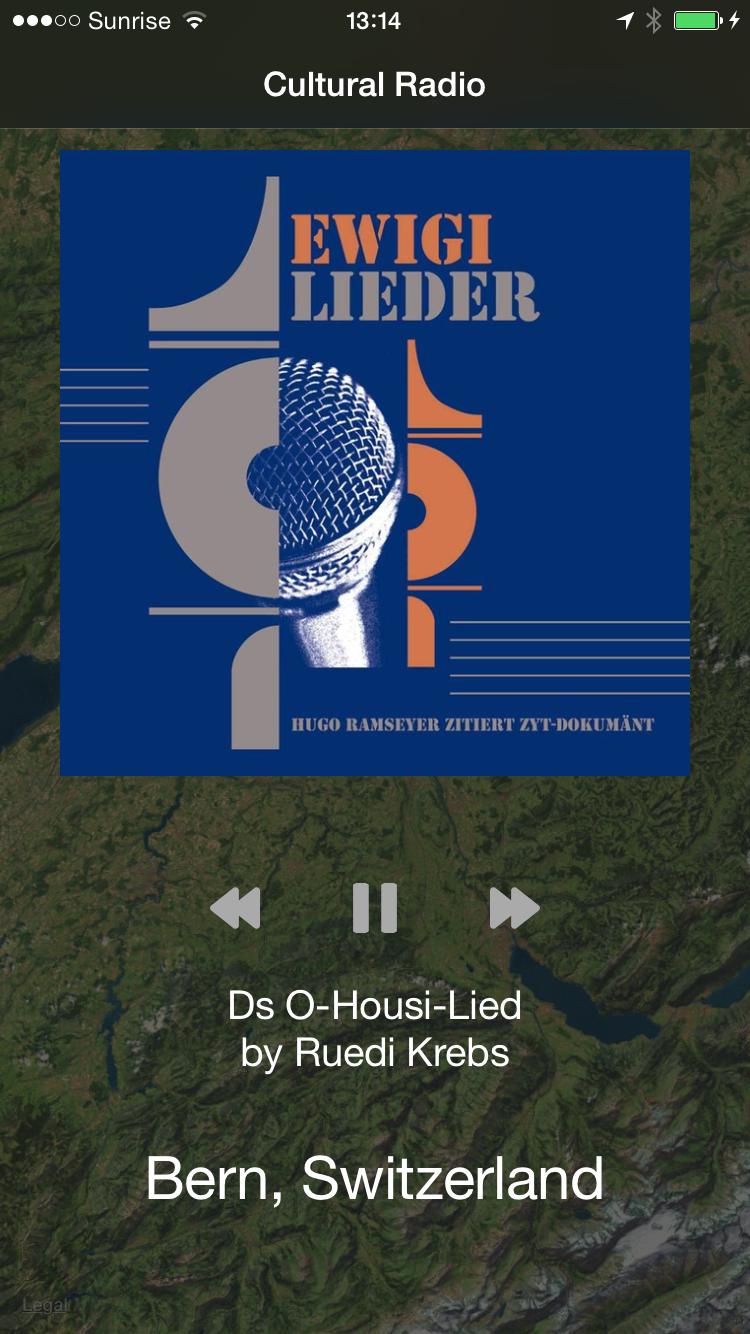
Cultural Music Radio

infoclio.ch Vorträge
Sabato, 28. Febbraio 2015
This is a cultural music radio which plays suitable music depending on your gps location or travel route. Our backend server looks for artists and musicians nearby the user's location and sends back an array of Spotify music tracks which will then be played on the iOS app.
Server Backend
We use a python server backend to process RESTful API requests. Clients can send their gps location and will receive a list of Spotify tracks which have a connection to this location (e.g. the artist / musician come from there).
Javascript Web Frontend
We provide a javascript web fronted so the services can be used from any browser. The gps location is determined via html5 location services.
iOS App
In our iOS App we get the user's location and send it to our python backend. We then receive a list of Spotify tracks which will be then played via Spotify iOS SDK.
There is also a map available which shows where the user is currently located and what is around him.
We offer a nicely designed user interface which allows users to quickly switch between music and map view to discover both environment and music! ![]()
Data and APIs
-
MusicBrainz for linking locations to artists and music tracks
-
Spotify for music streaming in the iOS app (account required)
Team
Diplomatic Documents and Swiss Newspapers in 1914

infoclio.ch Vorträge
Sabato, 28. Febbraio 2015
This project gathers two data sets: Diplomatic Documents of Switzerland and Le Temps Historical Archive for year 1914. Our aim is to find links between the two data sets to allow users to more easily search the corpora together. The project is composed by two parts:
- The Geographical Browser of the corpora. We extract all places from Dodis metadata and all places mentioned in each article of Le Temps, we then match documents and articles that refer to the same places and visualise them on a map for geographical browsing.
- The Text similarity search of the corpora. We train two models on the Le Temps corpus: Term Frequency Inverse Document Frequency and Latent Semantic Indexing with 25 topics. We then develop a web interface for text similarity search over the corpus and test it with Dodis summaries and full text documents.
Data and source code
-
Data.zip (CC BY 4.0) (DropBox)
Documentation
In this project, we want to connect newspaper articles from Journal de Genève (a Genevan daily newspaper) and the Gazette de Lausanne to a sample of the Diplomatic Documents in Switzerland database (Dodis). The goal is to conduct requests in the Dodis descriptive metadata to look for what appears in a given interval of time in the press by comparing occurrences from both data sets. Thus, we should be able to examine if and how the written press reflected what was happening at the diplomatic level. The time interval for this project is the summer of 1914.
In this context, at first we cleaned the data, for example by removing noise caused by short strings of characters and stopwords. The cleansing is a necessary step to reduce noise in the corpus. We then compared prepared tfidf vectors of words and LSI topics and represented each article in the corpus as such. Finally, we indexed the whole corpus of Le Temps to prepare it for similarity queries. THe last step was to build an interface to search the corpus by entering a text (e.g., a Dodis summary).
Difficulties were not only technical. For example, the data are massive: we started doing this work on fifteen days, then on three months. Moreover, some Dodis documents were classified (i.e. non public) at the time, therefore some of the decisions don't appear in the newspapers articles. We also used the TXM software, a platform for lexicometry and text statistical analysis, to explore both text corpora (the DODIS metadata and the newspapers) and to detect frequencies of significant words and their presence in both corpora.
Dodis Map

Team
Graphing the Stateless People in Carl Durheim's Photos

infoclio.ch Vorträge
Sabato, 28. Febbraio 2015

CH-BAR has contributed 222 photos by Carl Durheim, taken in 1852 and 1853, to Wikimedia Commons. These pictures show people who were in prison in Bern for being transients and vagabonds, what we would call travellers today. Many of them were Yenish. At the time the state was cracking down on people who led a non-settled lifestyle, and the pictures (together with the subjects' aliases, jobs and other information) were intended to help keep track of these “criminals”.
Since the photos' metadata includes details of the relationships between the travellers, I want to try graphing their family trees. I also wonder if we can find anything out by comparing the stated places of origin of different family members.
I plan to make a small interactive webapp where users can click through the social graph between the travellers, seeing their pictures and information as they go.
I would also like to find out more about these people from other sources … of course, since they were officially stateless, they are unlikely to have easily-discoverable certificates of birth, death and marriage.
-
Source code: downloads photographs from Wikimedia, parses metadata and creates a Neo4j graph database of people, relationships and places
Data
- Category:Durheim portraits contributed by CH-BAR on Wikimedia
Team
Links
Historical Tarot Freecell

infoclio.ch Vorträge
Sabato, 28. Febbraio 2015

Historical playing cards are witnesses of the past, icons of the social and economic reality of their time. On display in museums or stored in archives, ancient playing cards are no longer what they once were meant to be: a deck of cards made for playful entertainment. This project aims at making historical playing cards playable again by means of the well-known solitaire card game "Freecell".

 Tarot Freecell is a fully playable solitaire card game coded in HTML 5. It offers random setup, autoplay, reset and undo options. The game features a historical 78-card deck used for games and divination. The cards were printed in the 1880s by J. Müller & Cie., Schaffhausen, Switzerland.
Tarot Freecell is a fully playable solitaire card game coded in HTML 5. It offers random setup, autoplay, reset and undo options. The game features a historical 78-card deck used for games and divination. The cards were printed in the 1880s by J. Müller & Cie., Schaffhausen, Switzerland.
The cards need to be held upright and use Roman numeral indexing. The lack of modern features like point symmetry and Arabic numerals made the deck increasingly unpopular.
Due to the lack of corner indices - a core feature of modern playing cards - the vertical card offset needs to be significantly higher than in other computer adaptations.
Instructions
Cards are dealt out with their faces up into 8 columns until all 52 cards are dealt. The cards overlap but you can see what cards are lying underneath. On the upper left side there is space for 4 cards as a temporary holding place during the game (i.e. the «free cells»). On the upper right there is space for 4 stacks of ascending cards to begin with the aces of each suit (i.e. the «foundation row»).
Look for the aces of the 4 suits – swords, sticks, cups and coins. As soon as the aces are free (which means that there are no more cards lying on top of them) they will flip to the foundation row. Play the cards between the columns by creating lines of cards in descending order, alternating between swords/sticks and cups/coins. For example, you can place a swords nine onto a coins ten, or a cups jack onto a sticks queen.
Placing cards onto free cells (1 card per cell only) will give you access to other cards in the columns. Look for the lower numbers of each suit and move cards to gain access to them. You can move entire stacks, the number of cards moveable at a time is limited to the number of free cells (and empty stacks) plus one.
The game strategy comes from moving cards to the foundations as soon as possible. Try to increase the foundations evenly, so you have cards to use in the columns. If «Auto» is switched on, cards no other card can be placed on will automatically flip to the foundations.
You win the game when all 8 columns are sorted in descending order. All remaining cards will then flip to the foundations, from ace to king in each suit.
Updates
2015/02/27 v1.0: Basic game engine
2015/02/28 v1.1: Help option offering modern suit and value indices in the upper left corner
2015/03/21 v1.1: Retina resolution and responsive design
Data
- Wikipedia: Tarot 1JJ
- Wikimedia Commons: Tarot 1JJ card set
Author
- Prof. Thomas Weibel, Thomas Weibel Multi & Media
Historical Views of Zurich Data Upload
infoclio.ch Vorträge
Sabato, 28. Febbraio 2015
Preparation of approx. 200 historical photographs and pictures of the Baugeschichtliches Archiv Zurich for upload unto Wikimedia Commons. Metadata enhancing, adding landmarks and photographers as additional category metadata
Team
- Micha Rieser
- Reto Wick
- wild
- Marco Sieber
- Martin E. Walder
- and other team members
Lausanne Historic GeoGuesser
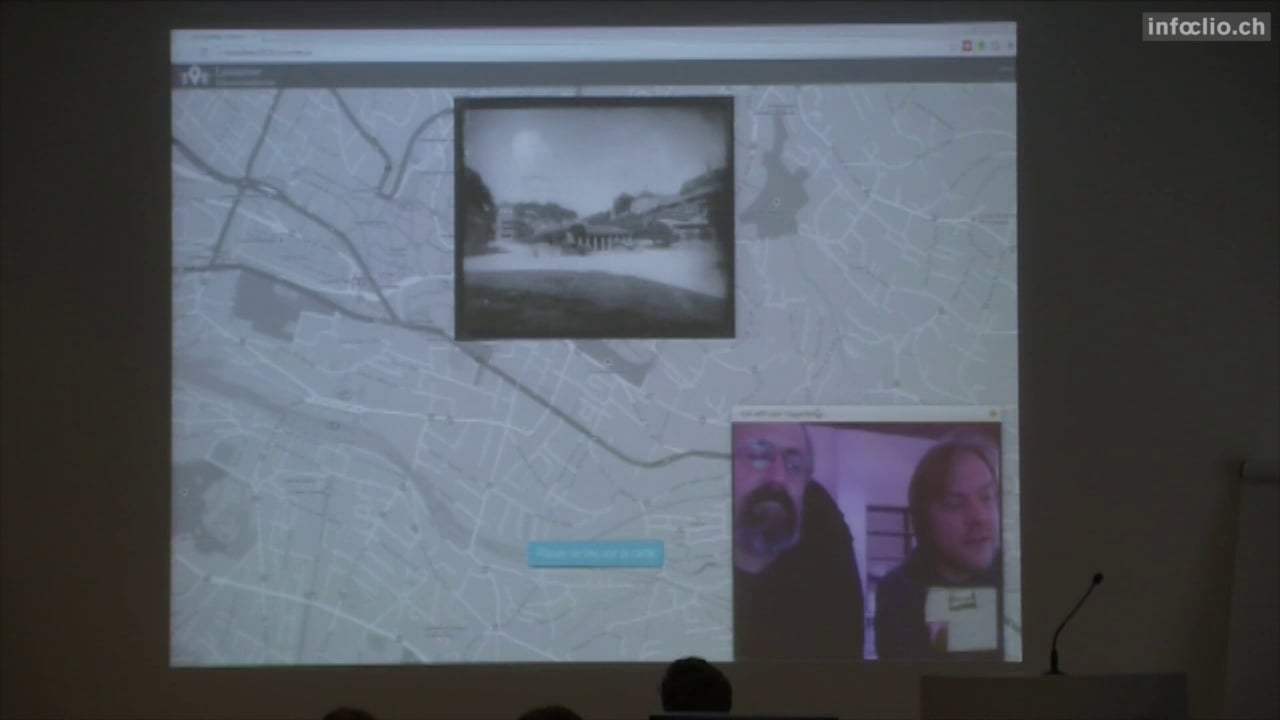
infoclio.ch Vorträge
Sabato, 28. Febbraio 2015

http://hackathon2015.cruncher.ch/
A basic GeoGuesser game using pictures of Lausanne from the 19th century. All images are available on http://musees.lausanne.ch/ and are are part of the Musée Historique de Lausanne Collection.
Data
Team
Oldmaps online

infoclio.ch Vorträge
Sabato, 28. Febbraio 2015

screenshot: georeferencer

screenshot: map from Ryhiner collection in oldmapsonline
Integrate collections of historical Swiss maps into the open platform www.oldmapsonline.org. At least the two collections Rhyiner (UB Bern) and manuscript maps from Zentralbibliothek Zurich.
Pilot for georeferencing maps from a library (ZBZ).
Second goal: to load old maps into a georefencing system and create a competition for public.
For the hackathon maps and metadata will be integrated in the mentioned platform. At the moment the legal status of metadata from Swiss libraries is not yet clear and only a few maps are in public domain (collection Ryhiner at UB Bern).
Another goal is to create a register of historical maps from Swiss collections.
Data
-
www.zumbo.ch old maps from a private collection (Marcel Zumstein).
-
Sammlung Ryhiner (University Library Bern): published in public domain
-
Here is the webpage for the georeferencing competition: http://klokan.github.io/openglambern/
-
georeferencing tool (by klokan) with random map: http://zumbo.georeferencer.com/random
Team
-
Peter Pridal, Günter Hipler, Rudolf Mumenthaler
Links
-
Documentation: Google Doc of #glamhack
-
Blog or forum posts will follow…
-
Tools we used: http://project.oldmapsonline.org/contribute for the metadata scheme (spreadsheet);
OpenGLAM Inventory

Gfuerst, CC by-sa 3.0, via Wikimedia Commons
infoclio.ch Vorträge
Sabato, 28. Febbraio 2015
Idea: Create a database containing all the heritage institutions in Switzerland. For each heritage institution, all collections are listed. For each collection the degree of digitization and the level of openness are indicated: metadata / content available in digital format? available online? available under an open license? etc. - The challenge is twofold: First, we need to find a technical solution that scales well over time and across national borders. Second, the processes to regularly collect data about the collections and their status need to be set up.
Step 1: Compilation of various existing GLAM databases (done)
National inventories of heritage institutions are created as part of the OpenGLAM Benchmark Survey; there is also a network of national contacts in a series of countries which have been involved in a common data collection exercise.
Step 2: GLAM inventory on Wikipedia (ongoing)
Port the GLAM inventory to Wikipedia, enrich it with links to existing Wikipedia articles: See
German Wikipedia|Project "Schweizer Gedächtnisinstitutionen in der Wikipedia".
Track the heritage institutions' presence in Wikipedia.
Encourage the Wikipedia community to write articles about institutions that haven't been covered it in Wikipedia.
Once all existing articles have been repertoried, the inventory can be transposed to Wikidata.
Further steps
-
Provide a basic inventory as a Linked Open Data Service
-
Create an inventory of collections and their accessibility status
Data
-
Swiss GLAM Inventory (Datahub)
Team
-
various people from the Wikipedia communtiy
-
and maybe you?
Picture This

infoclio.ch Vorträge
Sabato, 28. Febbraio 2015
A connected picture frame displaying historic images

Story
-
The Picture This “smart” frame shows police photographs of homeless people by Carl Durheim (1810-1890)
-
By looking at a picture, you trigger a face detection algorithm to analyse both, you and the homeless person
-
The algorithm detects gender, age and mood of the person on the portrait (not always right)
-
You, as a spectator, become part of the system / algorithm judging the homeless person
-
The person on the picture is at the mercy of the spectator, once again


How it works
-
Picture frame has a camera doing face detection for presence detection
-
Pictures have been pre-processed using a cloud service
-
Detection is still rather slow (should run faster on the Raspi 2)
-
Here's a little video https://www.flickr.com/photos/tamberg/16053255113/



Questions (not) answered
-
Who were those people? Why were they homeless? What was their crime?
-
How would we treat them? How will they / we be treated tomorrow? (by algorithms)
Data
Team
-
@ram00n
-
@tamberg
-
and you
Ideas/Iterations
-
Download the pictures to the Raspi and display one of them (warmup)
-
Slideshow and turning the images 90° to adapt to the screensize
-
Play around with potentiometer and Arduino to bring an analog input onto the Raspi (which only has digital I/O)
-
Connect everything and adapt the slideshow speed with the potentiometer
-
Display the name (extracted from the filename) below the picture
next steps, more ideas:
-
Use the Raspi Cam to detect a visitor in front of the frame and stop the slideshow
-
Use the Raspi Cam to take a picture of the face of the visitor
-
Detect faces in the camera picture
-
Detect faces in the images [DONE, manually, using online service]
-
…merge visitor and picture faces

Material
-
7inch TFT https://www.adafruit.com/products/947
-
Picture frame http://www.thingiverse.com/thing:702589
Software
-
http://www.raspberrypi.org/downloads/ - Raspbian
-
http://www.pygame.org - A game framework, allows easy display of images
-
https://bitbucket.org/tamberg/makeopendata/src/tip/2015/PictureThis - Scraper and Display
Links
-
http://www.raspberrypi.org/facial-recognition-opencv-on-the-camera-board/ - OpenCV on Raspi-Cam
-
https://speakerdeck.com/player/083e55006e4a013063711231381528f7 - Slide 106 for face replacement
Not used this time, but might be useful
-
https://thinkrpi.wordpress.com/2013/05/22/opencv-and-camera-board-csi/ - old Raspian versions did not have the latest OpenCV installed. Nice howto for that
-
https://realpython.com/blog/python/face-recognition-with-python/ - OpenCV, nice but not used
-
http://docs.opencv.org - not used directly, only via SimpleCV
-
http://makezine.com/projects/pi-face-treasure-box/ - maybe a nice weekend project
-
http://www.aliexpress.com/item/FreeShipping-Banana-Pro-Pi-7-inch-LVDS-LCD-Module-7-Touch-Screen-F-Raspberry-Pi-Car/32246029570.html - 7inch TFT mit LVDS Flex Connector
Portrait Id

infoclio.ch Vorträge
Sabato, 28. Febbraio 2015
(Original working title: Portrait Domain)

This is a concept for an gamified social media platform / art installation aiming to explore alternate identity, reflect on the usurping of privacy through facial recognition technology, and make use of historic digitized photographs in the Public Domain to recreate personas from the past. Since the #glamhack event where this project started, we have developed an offline installation which uses Augmented Reality to explore the portraits. See videos on Twitter or Instagram.
View the concept document for a full description.
Data
The exhibit gathers data on user interactions with historical portraits, which is combined with analytics from the web application on the Logentries platform:

Team
Launched by loleg at the hackdays, this project has already had over a dozen collaborators and advisors who have kindly shared time and expertise in support. Thank you all!
Please also see the closely related projects picturethis and graphing_the_stateless.
Links
Public Domain Game

infoclio.ch Vorträge
Sabato, 28. Febbraio 2015

A card game to discover the public domain. QR codes link physical cards with data and digitized works published online. This project was started at the 2015 Open Cultural Data Hackathon.
Sources
Team
-
Mario Purkathofer
-
Joël Vogt
-
Bruno Schlatter
Schweizer Kleinmeister: An Unexpected Journey

infoclio.ch Vorträge
Sabato, 28. Febbraio 2015

This project shows a large image collection in an interactive 3D-visualisation. About 2300 prints and drawings from “Schweizer Kleinmeister” from the Gugelmann Collection of the Swiss National Library form a cloud in the virtual space.
The images are grouped according to specific parameters that are automatically calculated by image analysis and based on metadata. The goal is to provide a fast and intuitive access to the entire collection, all at once. And this not accomplished by means of a simple list or slideshow, where items can only linearly be sorted along one axis like time or alphabet. Instead, many more dimensions are taken into account. These dimensions (22 for techniques, 300 for image features or even 2300 for descriptive text analysis) are then projected onto 3D space, while preserving topological neighborhoods in the original space.
The project renounces to come up with a rigid ontology and forcing the items to fit in premade categories. It rather sees clusters emerge from attributes contained in the images and texts themselves. Groupings can be derived but are not dictated.
The user can navigate through the cloud of images. Clicking on one of the images brings up more information about the selected artwork. For the mockup, three different non-linear groupings were prepared. The goal however is to make the clustering and selection dependent on questions posed by any individual user. A kind of personal exhibition is then curated, different for every spectator.
Open Data used
Gugelmann Collection, Swiss National Library
http://opendata.admin.ch/en/dataset/sammlung-gugelmann-schweizer-kleinmeister
http://commons.wikimedia.org/wiki/Category:CH-NB-Collection_Gugelmann
Team
-
Sonja Gasser ( @sonja_gasser)